
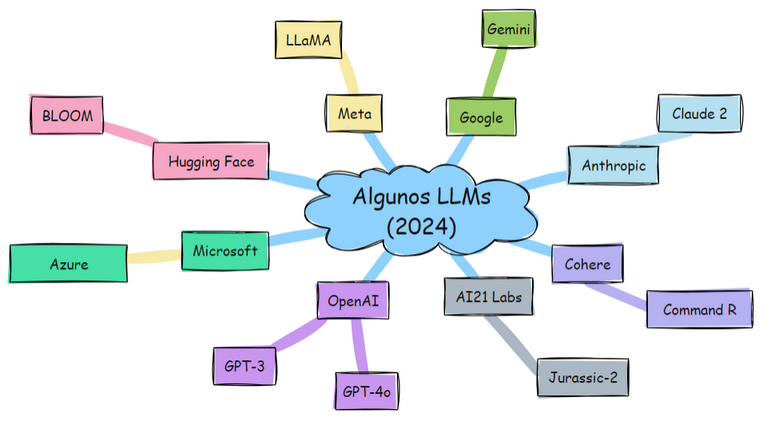
Un LLM es un sistema de procesado del lenguaje natural. El procesamiento del lenguaje natural (NLP, por sus siglas en inglés) ha experimentado avances significativos en los últimos años, gracias al auge de la inteligencia artificial y al desarrollo de modelos de lenguaje cada vez más potentes. Los modelos de lenguaje se utilizan para comprender y generar texto en un formato similar al humano, facilitando tareas como la traducción automática, el análisis de sentimientos o los asistentes virtuales.
En este contexto, los Large Language Models (LLM), o modelos de lenguaje de gran tamaño, han ganado protagonismo. Estas IA son capaces de generar textos complejos y coherentes, manteniendo conversaciones casi indistinguibles de las de un ser humano. En este post, profundizaremos en qué es un LLM, cómo funcionan, en qué aplicaciones se utilizan y qué retos y limitaciones presentan.
Definición de LLM
Un LLM es un modelo de lenguaje entrenado utilizando una técnica de programación llamada redes neuronales profundas, diseñado para procesar computacionalmente («entender») de manera estadística, y generar texto que aparenta una respuesta humana. Se denominan grandes porque están entrenados con enormes cantidades de datos textuales y contienen millones, e incluso billones de parámetros que ajustan la forma en que estos modelos procesan el lenguaje.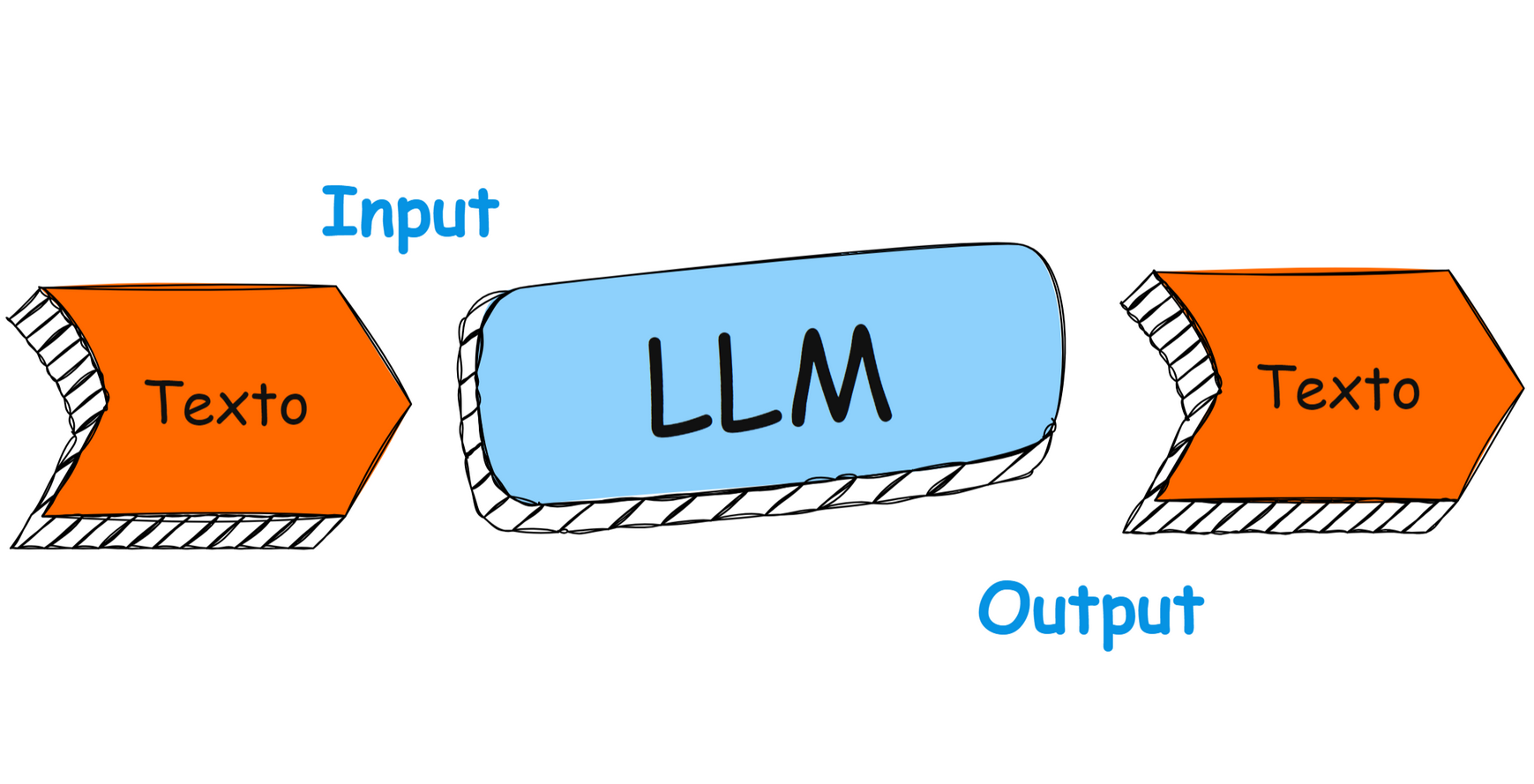
Los LLM se basan en unos conceptos matemáticos llamados transformadores, que se programan como un tipo de red neuronal que ha revolucionado el campo del procesado del lenguaje natural. Los modelos tradicionales de lenguaje solían tener un número limitado de parámetros y estaban diseñados para tareas específicas. En contraste, los LLM son versátiles, lo que les permite realizar una amplia variedad de tareas relacionadas con el lenguaje, desde responder preguntas hasta generar código.
Lo que diferencia a los LLM de otros modelos más pequeños es su capacidad para captar patrones estadísticos sutiles en los datos, aprender relaciones complejas entre palabras y generar respuestas más precisas y contextuales. Esta mayor escala permite a los LLM sobresalir en tareas que requieren un entendimiento profundo del contexto.
Cómo funciona un LLM
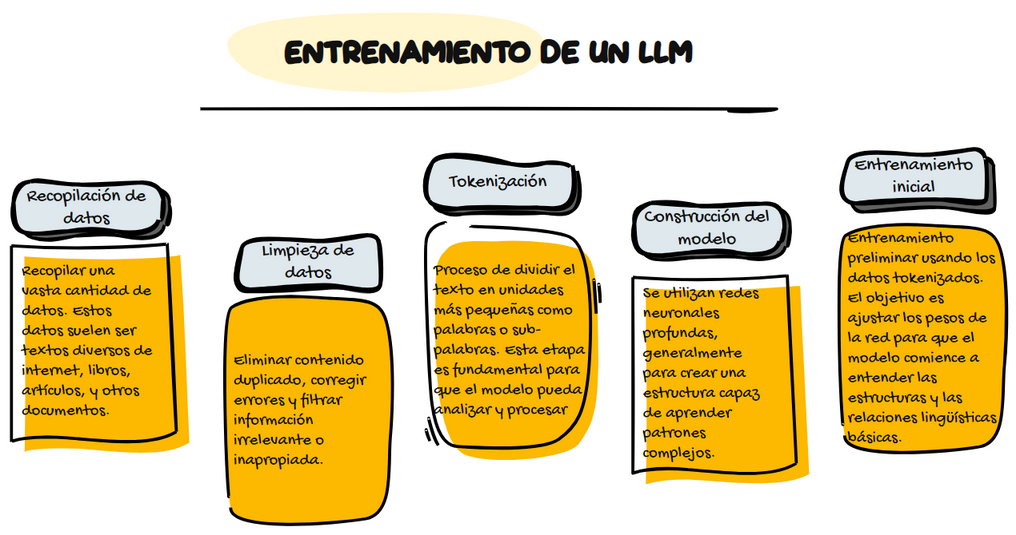
El funcionamiento de un LLM se basa en dos fases principales: el preentrenamiento y el fine-tuning. En la fase de preentrenamiento, el modelo se alimenta con grandes cantidades de datos textuales, como libros, artículos o sitios web. A través de este proceso, el modelo aprende a predecir la siguiente palabra en una secuencia de texto. Cuantos más datos se utilicen, mejor será su capacidad para capturar patrones y entender el contexto lingüístico. El entrenamiento es complejo pero la imagen siguiente esquematiza los pasos que siguen los desarrolladores de IA.
Un concepto clave en los LLM es el de (hiper)parámetros, que son los valores que la red neuronal ajusta durante el entrenamiento para mejorar su precisión. Cuantos más parámetros tenga un modelo, mayor es su capacidad para procesar y generar texto de manera coherente. Por ejemplo, GPT-3, uno de los LLM más conocidos, tiene 175 mil millones de parámetros, lo que le permite generar respuestas complejas y matizadas.
Una vez preentrenado, el LLM puede ajustarse o «fine-tunearse» para tareas específicas. Este ajuste fino permite al modelo especializarse en tareas concretas como la traducción, la generación de resúmenes o la respuesta a preguntas. Sin embargo, incluso sin este ajuste, los LLM muestran una sorprendente capacidad para adaptarse a tareas nuevas.
Entrenamiento de un LLM en Educación
Los diseñadores de IA desarrollan modelos mediante un proceso llamado entrenamiento. A continuación, un ejemplo de los pasos típicos que podría seguir un diseñador para construir un modelo que mejore la gestión del comportamiento en el aula:
- Definir el problema a resolver. Los diseñadores buscan crear un modelo que ayude a identificar comportamientos problemáticos en el aula para intervenir oportunamente y mejorar el ambiente de aprendizaje.
- Recopilar datos relevantes para el entrenamiento. Se recopilan datos sobre comportamientos de estudiantes, incluyendo registros de asistencia, incidencias disciplinarias y participación en clase.
- Preparar los datos para el entrenamiento. Se etiquetan características clave, como la frecuencia de interrupciones o tardanzas, y se anotan comportamientos positivos. Los datos se dividen en conjuntos de entrenamiento y validación.
- Entrenar el modelo. Aplican algoritmos de aprendizaje automático para que el modelo reconozca patrones en los datos que puedan indicar la necesidad de intervención, como alta frecuencia de interrupciones o descenso en la participación.
- Evaluar el modelo. Utilizan el conjunto de validación para evaluar la precisión y fiabilidad del modelo al predecir comportamientos problemáticos. Si el modelo no es preciso, los diseñadores pueden ajustar los datos o los algoritmos utilizados.
- Despliegue del modelo. Una vez satisfechos con el rendimiento, despliegan el modelo en una herramienta de IA que ayuda a los educadores a identificar problemas y aplicar estrategias de intervención de manera más efectiva.
El entrenamiento de modelos es un proceso repetitivo. Los diseñadores pueden repetir pasos y realizar ajustes hasta crear el mejor modelo posible. Tras el despliegue, el modelo debe ser monitoreado y ajustado continuamente según el feedback de los educadores y los desafíos que surjan en el entorno real. Este ciclo de mejora continua asegura que los modelos de IA sean precisos y versátiles, resultando en herramientas efectivas y fiables para el sector educativo.
Entender cómo se desarrollan los modelos de IA permite tomar decisiones informadas sobre cuándo y cómo utilizar una herramienta de IA para alcanzar tus objetivos educativos.
Usos de LLMs
Los LLM están teniendo un impacto profundo en una variedad de sectores. Algunas de las aplicaciones más destacadas incluyen:
- Asistentes virtuales: Los asistentes como Siri, Alexa o Google Assistant utilizan LLM para comprender y generar respuestas cada vez más precisas a las preguntas de los usuarios, mejorando la interacción entre humanos y máquinas.
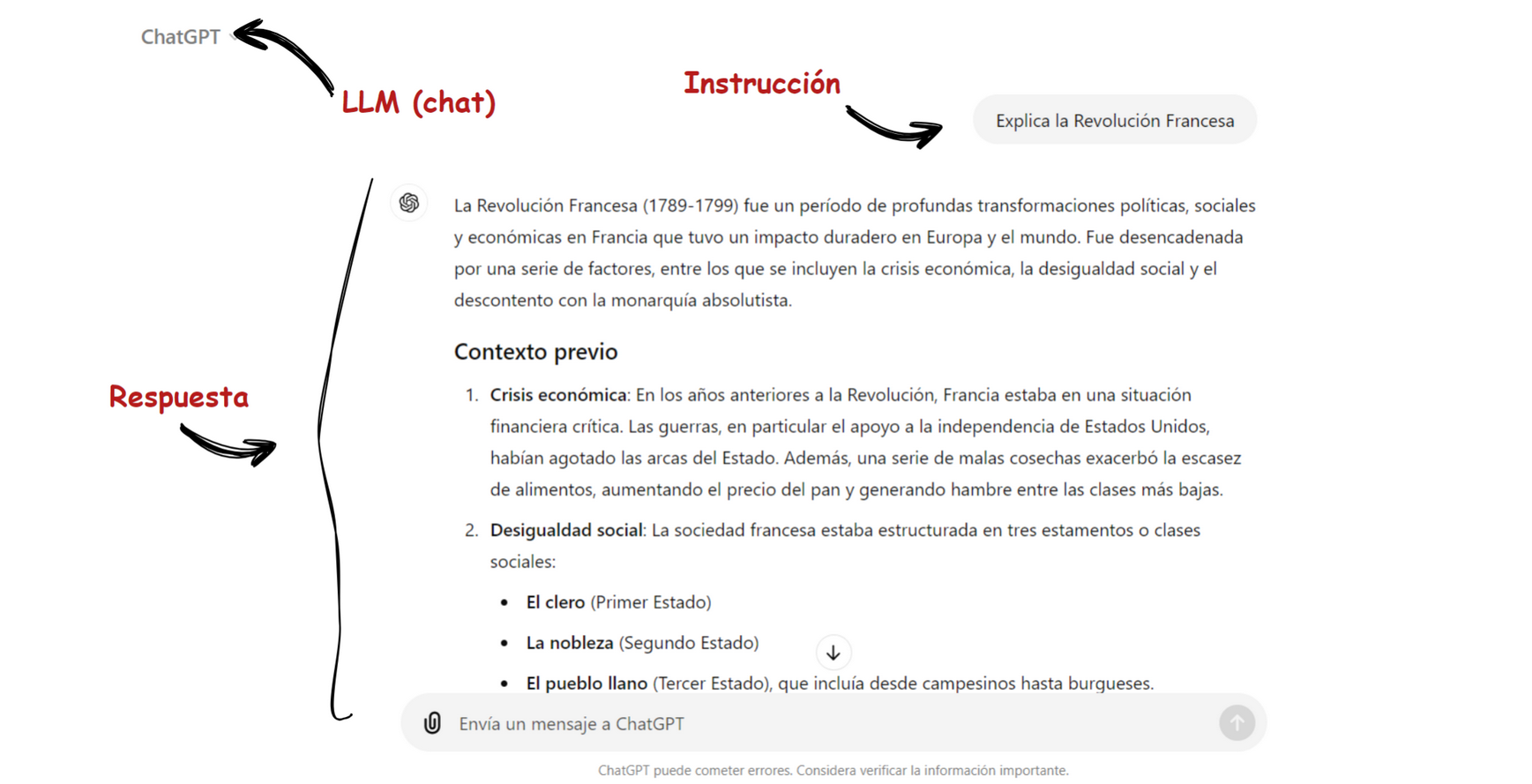
- Chatbots: Empresas de atención al cliente emplean LLM para crear chatbots que interactúan con los usuarios de manera más fluida y eficiente, resolviendo consultas comunes sin la intervención humana. En la imagen siguiente se puede ver un los componente básicos de ChatGPT, un LLM que tiene una interfaz de interacción tipo chat.
- Generación de contenido: Los LLM pueden generar textos como artículos, informes o incluso publicaciones en redes sociales, lo que facilita la creación automática de contenido relevante para diferentes audiencias.
- Traducción automática: Servicios como Google Translate emplean modelos de lenguaje para traducir texto de un idioma a otro, mejorando la precisión y el contexto de las traducciones.
| Empresa | LLM |
|---|---|
| Google Translate utiliza modelos de lenguaje como Neural Machine Translation (NMT) para ofrecer traducciones automáticas en más de 100 idiomas. | |
| DeepL | DeepL Translator emplea redes neuronales y modelos avanzados de lenguaje, ofreciendo alta precisión en traducciones entre varios idiomas. |
| Microsoft | Microsoft Translator utiliza Neural Machine Translation (NMT) para ofrecer traducciones automáticas en tiempo real dentro de su ecosistema de aplicaciones y servicios. |
| Meta (Facebook AI) | El modelo M2M-100 de Facebook AI es capaz de traducir directamente entre 100 idiomas sin depender del inglés como lengua intermedia. |
| Amazon | Amazon Translate es un servicio basado en modelos de lenguaje avanzados que proporciona traducción automática en más de 50 idiomas, disponible a través de AWS. |
- Educación: En el sector educativo, los LLM pueden generar explicaciones personalizadas y responder a preguntas complejas, ayudando a los estudiantes a aprender de manera más eficaz.
| LLM | Descripción |
|---|---|
| Socratic | Utiliza modelos de lenguaje para ayudar a los estudiantes a resolver problemas y responder preguntas en diversas asignaturas, proporcionando explicaciones detalladas adaptadas al nivel educativo. |
| Duolingo | Emplea LLMs para personalizar lecciones y ofrecer interacciones conversacionales naturales en el aprendizaje de idiomas, mejorando correcciones automáticas y retroalimentación. |
Además de estas aplicaciones, los LLM se utilizan en tareas como la generación de código, la investigación médica y el análisis de sentimientos en redes sociales. Su versatilidad y capacidad para adaptarse a nuevas tareas los convierte en herramientas valiosas en múltiples industrias.
Limitaciones de los LLMs
A pesar de sus impresionantes capacidades, los LLM enfrentan varios desafíos. Uno de los mayores problemas es el alto coste computacional asociado a su entrenamiento. Entrenar un LLM requiere una infraestructura masiva de computación y consume una cantidad considerable de energía, lo que plantea preocupaciones medioambientales. El usuario no especializado no suele ejecutar el LLM en su ordenador sino que utiliza servicios en la nube de empresas que lo comercializan. En cualquier caso, hay que tener en cuenta ciertas limitaciones actuales (2024) de los LLMs para poder tener expectativas realistas y usarlos adecuadamente sin frustrarnos.
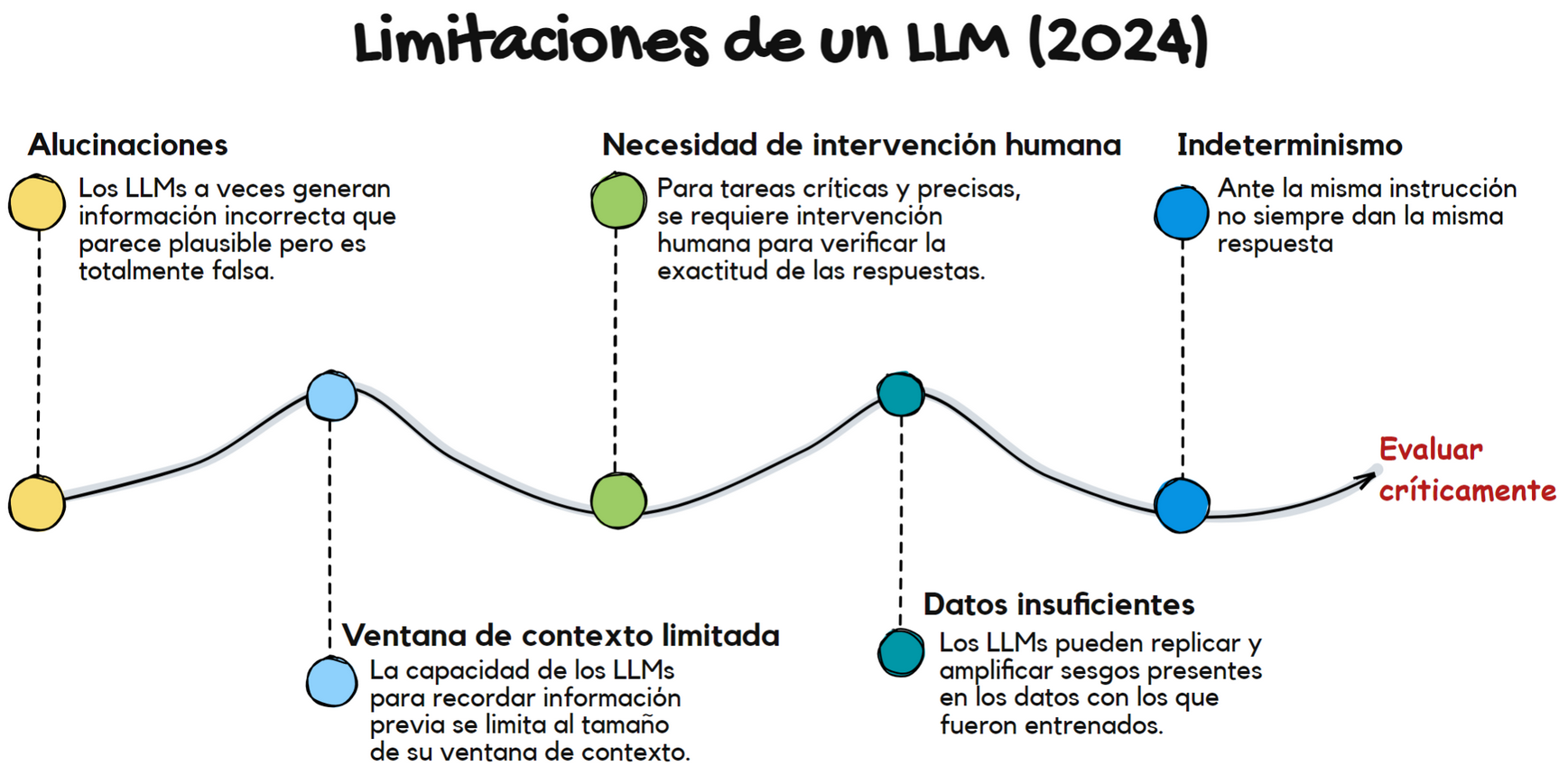
Otro reto importante es el sesgo en los datos. Los LLM se entrenan con grandes volúmenes de texto disponibles en internet, lo que significa que pueden absorber y amplificar los sesgos presentes en esos datos. Esto puede llevar a que los modelos generen respuestas discriminatorias o desinformadas, lo que plantea cuestiones éticas sobre su uso.
También existen preocupaciones sobre la privacidad, los sesgos o falta de datos suficientes y los posibles malusos de los LLM. Estos modelos pueden ser utilizados para generar desinformación, contenido ofensivo o incluso para manipular opiniones en plataformas digitales. Estos riesgos han suscitado debates sobre cómo regular el uso de los LLM y cómo garantizar que se utilicen de manera responsable.
Otro fenómeno son las alucinaciones: respuestas aparentemente bien estructuradas pero que son falsas. Los modelos usan patrones estadísticas que existen entre palabras, no entienden del significado como lo hacemos los humanos y no saben si es real o no la respuesta que dan. Solo pueden corregirse con feedback sobre dichas respuestas.
Es por esto que es necesario lo que se denomina hombre en el bucle (man in the loop), es decir, la supervisión e intervención del ser humano tanto a la hora de darle instrucciones -ingeniería de prompts- como a la hora de evaluar críticamente las respuestas.
Por último, hay que destacar que los LLMs son indeterministas, es decir, ante una misma instrucción, pueden dar respuestas diferentes cada vez que se ejecuta.
Conclusión
Los LLMs representan, por tanto, un avance revolucionario en el campo del procesamiento del lenguaje natural. Gracias a su capacidad para generar texto de manera coherente y comprender el contexto de las conversaciones, están transformando la forma en que interactuamos con la tecnología. Desde asistentes virtuales hasta chatbots y generadores de contenido, los LLM están presentes en numerosos aspectos de nuestra vida diaria. El futuro de los LLMs es prometedor, y a medida que continúen mejorando, es probable que veamos aún más aplicaciones innovadoras que cambien la forma en que nos comunicamos y procesamos la información.
Referencias
Vaswani, A., et al. (2017). Attention is All You Need.
Artículo que introdujo la arquitectura de transformadores, fundamental para el desarrollo de los LLM. Disponible en:https://arxiv.org/abs/1706.03762Brown, T., et al. (2020). Language Models are Few-Shot Learners.
Documento clave sobre GPT-3, un LLM con 175 mil millones de parámetros. Explora cómo los LLM pueden resolver tareas con pocos ejemplos. Disponible en:
https://arxiv.org/abs/2005.14165Devlin, J., et al. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
BERT es uno de los modelos predecesores más importantes en el campo del NLP y de los LLM. Disponible en:
https://arxiv.org/abs/1810.04805OpenAI. GPT-3: An Autoregressive Language Model.
Página oficial de OpenAI que detalla el funcionamiento de GPT-3, uno de los LLM más conocidos. Versión de MEDIUM disponible en:
https://openai.com/research/gpt-3Ruder, S. (2019). Transfer Learning in Natural Language Processing.
Un artículo que explica cómo el aprendizaje por transferencia se aplica en modelos como los LLM para especializarse en tareas específicas. Disponible en:
https://ruder.io/transfer-learning/Bender, E. M., et al. (2021). On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?.
Un artículo crítico sobre los riesgos éticos y medioambientales de los LLM. Disponible en:
https://dl.acm.org/doi/10.1145/3442188.3445922